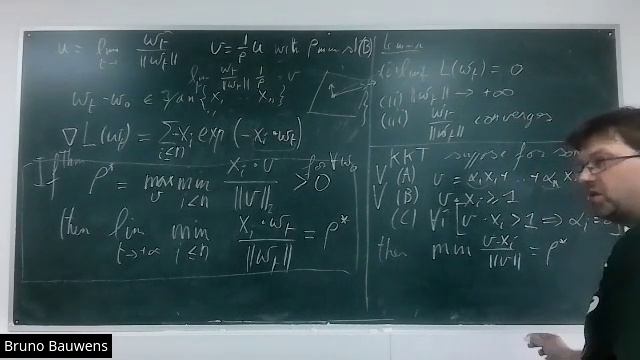BrunosTCSlectures - видео - все видео
Новые видео из канала RuTube на сегодня - 19 April 2026 г.
Новые видео из канала RuTube на сегодня - 19 April 2026 г.
- Proof that parameter updates in wide networks have small norm - Neural tangent kernel and its min-eigenvalue - Solving linear systems with gradient descent, condition number, link to double descent - Label dependent bound on the distance and optional tasks (see chapter 18 of the notes) Course website http://wiki.cs.hse.ru/Statistical_learning_theory_2025- Examples of better time bounds for brute force searches - Solving vertex clover in time (1.4645)^k * poly(n) time - Definition of the class FPT - Examples of the kernel technique - Mathematical definition of a kernel - See lecture notes for the proof that a kernel exists if and only if the problem is FPT Course website: http://wiki.cs.hse.ru/Theory_of_computation_2025-- Exponential time hypothesis (ETH) -- ETH implies that the problems 3COL, IND-SET, CLIQUE are not in TIME(2^{o(n)}) -- The EDGE-CLIQUE-COVER problem is FPT, runtime 2^{k^2 * 2^k} * poly(n) -- The double exponent above is necessary (without proof) -- ETH implies that CLIQUE is not FPT. In fact, for each computable f and g(k) ﹤= o(k), CLIQUE is not in TIME(f(k) n^{g(k)} -- Parameterized reductions, examples -- Classes W[t]. CLIQUE is in W[1]. -- CLIQUE is complete for W[1], DOM-SET and SET-COVER is complete for W[2]. Course website http://wiki.cs.hse.ru/Theory_of_computation_2025- Neural nets are locally linear: calculation of the Hessian for nets with 1 hidden layer. - Exponential convergence of gradient descent on the linearised net - The PL-condition Course website: http://wiki.cs.hse.ru/Statistical_learning_theory_2025http://wiki.cs.hse.ru/Statistical_learning_theory_2025- 3 ways to deal with an NP-hard optimization problem - definition rho-approximation algorithm - A 2-approximation algorithm for vertex cover - The greedy vertex cover algorithm is not a constant factor approximation - An O(ln |X|)-approximation algorithm for the subsetcover problem - Definition PTAS and FPTAS approximation schemes. - If vertex cover, independent set, etc have an FPTAS, then P = NP. - PTAS for the makespan problem Course website http://wiki.cs.hse.ru/Theory_of_computation_2025Last 25 minutes are not so clear, you may check last year's movie https://www.youtube.com/watch?v=oU2AzubDXeo - Excess risk is bounded by Rademacher complexity (and fluctuation term): proof. - Rademacher complexity of linear functions with L1 and L2 regularization, - Risk bounds using Talagrand's contraction lemma - Hard margin SVM, derivation of objective, uniqueness of solution, dual form - Soft margin SVM - Margin risk, Hinge loss-- A simple mistake bound from semimeasures. -- There is no (computable) multiplicatively maximal semimeasure. -- There exists a lower semicomputable (lsc) that exceeds any other lsc semimeasure up to a constant. This measure is called algorithmic probability. -- Solomonoff's theorem on the convergence of conditional algorithmic probability to computable conditional probability. Course website: http://wiki.cs.hse.ru/Kolmogorov_complexity_fall2025-- (directed) reachability is in SPACE(log^2 n) -- PSPSACE = NPSPACE (Savitch'es theorem briefly) -- TQBF is PSPACE-complete -- Generalized geography is PSPACE-complete Course website: http://wiki.cs.hse.ru/Theory_of_computation_2025-- Bounded difference inequality -- Maximal inequality -- Rademacher complexity -- Basic properties and closure under convex combinations Course website: http://wiki.cs.hse.ru/Statistical_learning_theory_2025Measure concentration: Markov, Chebeyshev, Hoeffding bounds. Risk, bias optimal classifier, risk decomposition. Risk bounds for finite classes and bias complexity trade-off. Risk bound using VC-dimension (the proof is similar as in previous lecture, it will be for homework) Fundamental theorem of statistical learning theory. Course website: http://wiki.cs.hse.ru/Statistical_learning_theory_2025Plain complexity, -- Definition and simple properties -- log cardinality bound of sections of enumerable sets -- chain rule (symmetry of information) Course website: http://wiki.cs.hse.ru/Kolmogorov_complexity_fall2025Circuits: -- definition and examples, -- all predicates on n-bit inputs are computed by circuits of size O(2^n) -- some predicates are only computed by circuits of size at least 2^n/(2n) -- Definition of P/poly, AC^i, NC^i -- Reachability is in AC^1 Course website: http://wiki.cs.hse.ru/Theory_of_computation_2025Course Kolmogorov complexity, lecture 1 on 10.10.2025: http://wiki.cs.hse.ru/Kolmogorov_complexity_fall2025 Intro -- applications of Kolmogorov complexity in computational complexity -- 3 applications in machine learning (quick overview) Computability theory -- Turing machines -- Computable sets -- The Halting problem is not computable -- Enumerable sets -- Computable functions with integer, rational and real valuesPolynomial time reductions, examples, NP-completeness, completeness of IND-SET, 3colorability, positive 1-in-3SAT, subsetsum Course website: http://wiki.cs.hse.ru/Theory_of_computation_2025Follow the leader, randomized weighted majority algorithm, Jenssen's inequality, Hoeffding's inequality, exponentially weighted majority algorithm Course website: http://wiki.cs.hse.ru/Statistical_learning_theory_2025the standard optimal algorithm and the perceptron algorithm course website http://wiki.cs.hse.ru/Statistical_learning_theory_2025Course introduction to statistical learning theory, HSE, fall 2025. September 16, 2025. Course homepage: http://wiki.cs.hse.ru/Statistical_learning_theory_2025


![HSE Theory Of Computing, Lecture 11: Exponential Time Hypothesis, Clique Is Not FPT, Classes W[i]](http://pic.rtbcdn.ru/video/2025-12-05/7b/31/7b31433885149456376e7a09351b51a5.jpg)